
This research is an intersection of three different areas: computer architecture, reconfigurable computing, and design automation. The aim is to empower the FPGAs to become a much more efficient platform for high-performance power efficient execution of many emerging massively parallel applications (from AI and computer vision to scientific and big data computing). This research suggests a shift from synthesizing the computation-path toward synthesizing the entire application-specific system architecture with kernel-specific memory prefetcher and runtime thread scheduler to fully utilize the benefits and potential of reconfigurable fabric. This study aims to create a systematic way to integrate the proposed architecture optimizations (runtime prefetching and thread scheduling) into the OpenCL High-Level Synthesis.
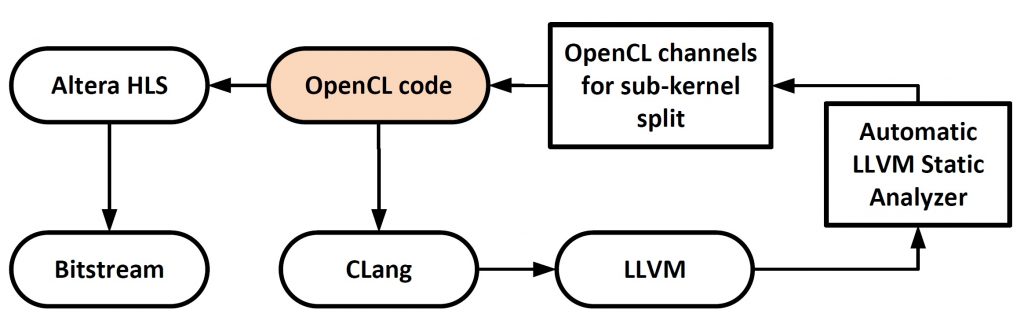
The advent of Open Source Programming Models like OpenCL for reconfigurable platforms like FPGAs has attracted many application developers and system architects for efficient execution of compute-intensive massively parallel applications. Our work is focused on identifying the major performance bottlenecks when executing OpenCL kernels on FPGAs and proposing both architectural and design level optimizations to remove those bottlenecks. Our philosophy is to provide easy-to-use, sustainable generic solutions that are scalable in nature so as to integrate with the ongoing FPGA research in the industry as well as academia.
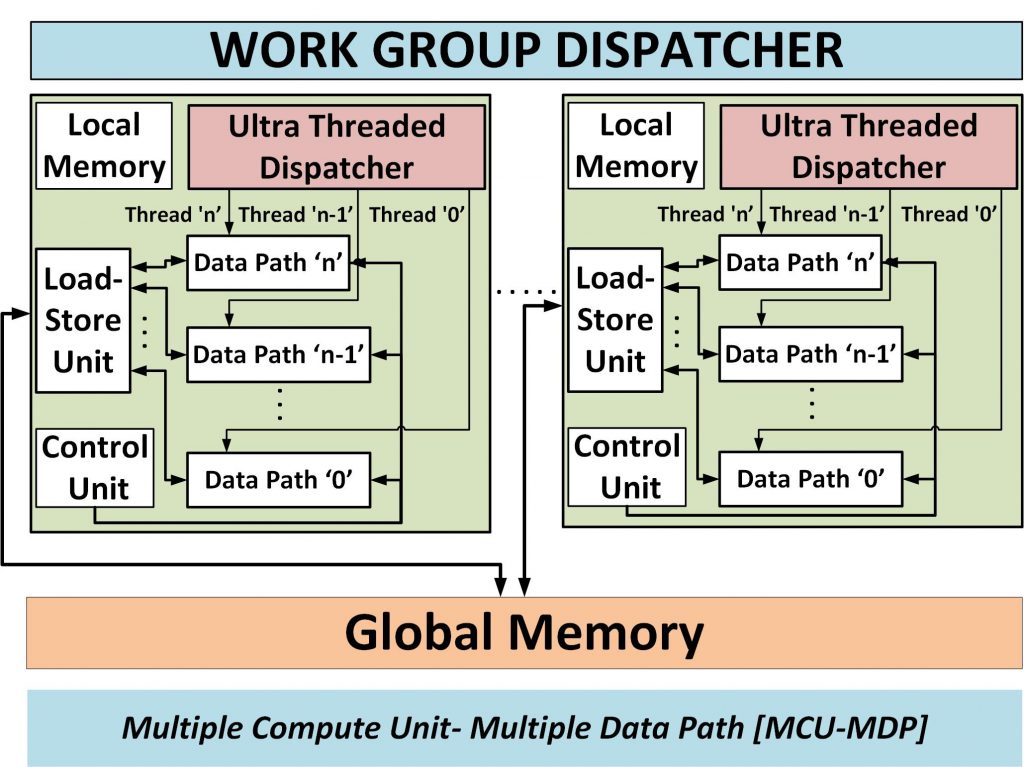
Current projects underway include;
- A novel LLVM based automation approach to enable memory decoupling in order to hide memory access latency thereby improving the overall throughput of massively parallel applications running on FPGAs. We use Intel Altera Stratix V FPGA device for this work.
- Machine learning applications that are both compute and memory intensive are employed in a diverse category of toolchains supported by the cutting edge Amazon Web Services [AWS] F1 EC2 cloud instance with state-of-art Xilinx VU9P FPGAs. Xilinx and AWS provides support for developing and running such applications on high-performance custom hardware acceleration.
Through the combination of such powerful computing resources and novel architecture for FPGAs, we foresee to achieve fruitful results in many domains such as machine learning training, inference and computer vision.



