
With the continuous growth in the complexity of deep learning algorithms, rapid architecture modeling and design space exploration is a must. To meet this need, one important aspect of my research at TeCSAR focuses on quick and scalable architecture modeling and design space exploration. To this end, we have created a custom runtime simulation engine that is capable of simulating application-specific hardware. Our simulation model leverages LLVM IR extracted from deep learning libraries (e.g. Google TensorFlow) with the capability of full system simulation and design space exploration for the diverse range of deep learning and machine learning algorithms. The LLVM IR provides a target-independent representation of an application without many of the overheads of higher level programming languages. Our proposed LLVM-based simulation execution engine takes an LLVM IR file as input and extracts the static Control Data Flow Graph (CDFG). During execution, it uses this static CDFG to construct a runtime graph, representing an application-specific datapath. By rapidly extracting of algorithm-specific data and instruction parallelism, our proposed simulation framework creates a cyclic-accurate computation model.
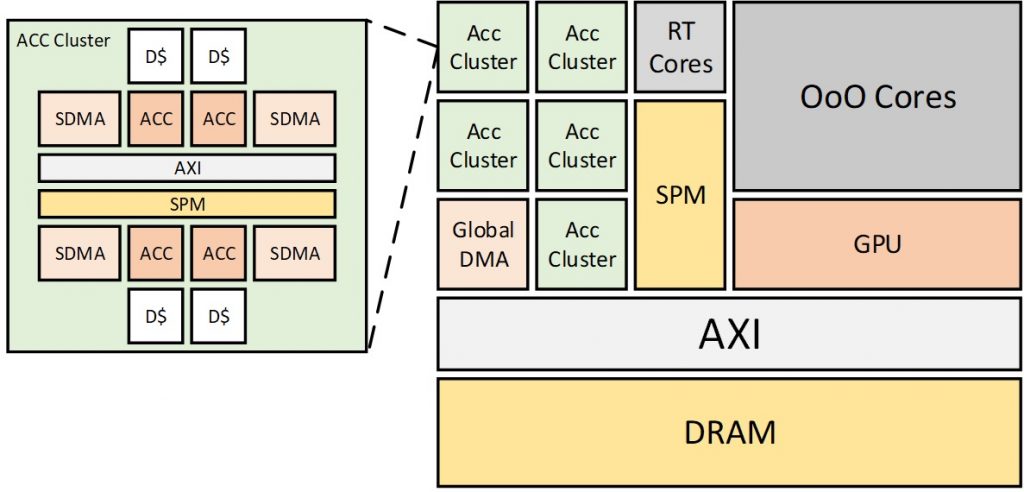
In order to develop highly efficient domain-specific hardware, we must first understand the core features that define an application domain. Often application domains rely heavily on high-level languages (HLL) with domain-specific APIs to simplify the programmer’s abstraction and enable intent-driven design. It is usually impractical to extract architecture insights from this level of abstraction. Likewise, it is impractical to perform binary-level analysis of applications due to the overheads imposed by architecture constraints obfuscating algorithm-intrinsic features. This is why my approach is focused on the Low-Level Virtual Machine (LLVM) abstraction. LLVM provides an assembly-like intermediate representation that is both source and target independent. It is often used in compilation workflows with multiple target devices (ex: Tensorflow XLA Compiler), to perform high-level optimizations without imposing the resource constraints of specific target architectures. In addition, the preservation of an explicit control and data flow graph (CDFG) makes it easier to understand algorithm-intrinsic semantics.
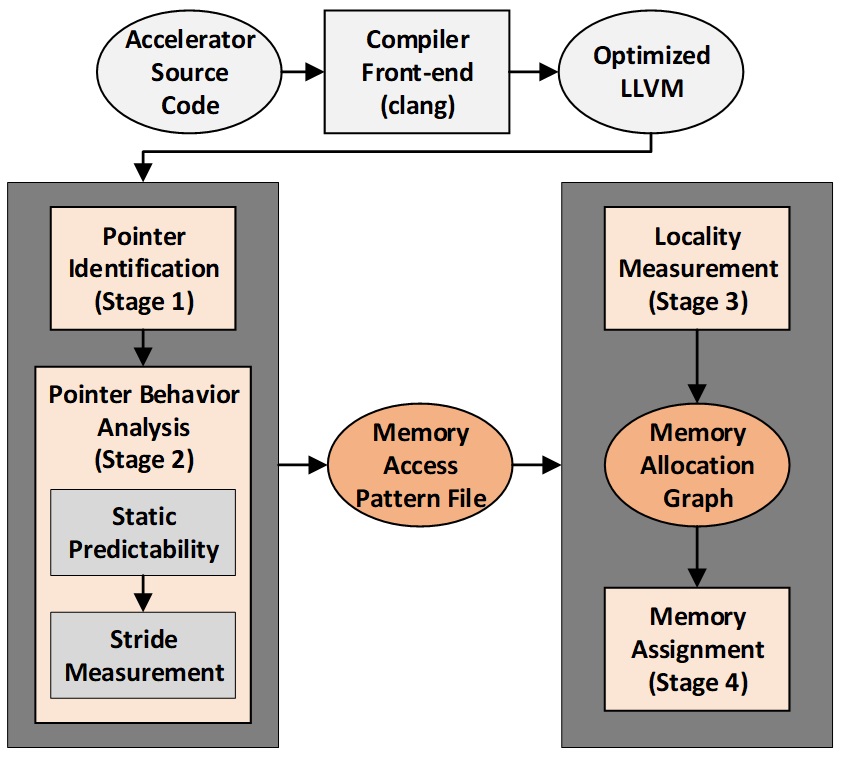
- Developing a series of tools and methodologies for extracting application domain features based on the LLVM abstraction. Our primary target domain will be deep learning as expressed in Tensorflow. Domain features of interest include dataflow and memory access, operational and functional composition, and algorithm intrinsic parallelism. Dataflow and memory access describe the way in which data moves through a system, be it through memory hierarchies, application datapaths, or between functional units. To this end we have developed and published a tool (https://github.com/samerogers/LocalityAwareMemoryAssignment) at the Design Automation Conference (DAC) (https://dl.acm.org/citation.cfm?id=3196070) that analyzes LLVM to understand the memory access semantic of an application and recommend a performance-per-power optimized memory hierarchy composed of caches and scratchpad memories. We are extending this analysis from single application to a set of applications that are representative of a domain to suggest memory hierarchies tuned to best support that domain. Operational and functional composition describe the core functionality of an algorithm and define the hardware functional units needed to construct a datapath. While many application domains rely heavily on function APIs, a purely functional analysis may often be too coarse to identify more common operations and potential reuse among functional units. Many simple composable operation units can exploit reuse and lead to reduced on chip area and routing demands over larger function-level units. Algorithm intrinsic parallelism refers not only to instruction and data level parallelism, but also to function and task level parallelism.
- Exploring and evaluating architecture solutions that exploit domain features identified in my first task. We are currently developing a cycle-accurate simulator for application-specific hardware and integrated it into the gem5 system accelerator to be released to the public in the near future. This simulator uses a static LLVM trace of an application to develop an application-specific datapath. Coupled with a custom set of hardware IPs such as DMAs and assorted I/Os, as well as the design space flexibility of gem5 and extensions like gem5-gpu, I can simulate the interaction of many heterogeneous devices across an assortment of system typologies. This system design tool, along with the domain analysis tools, will be made open source and available to anyone who wishes to explore application and domain-specific architectures.
Outcomes:
Enabling application domain analysis and design optimization for innovative Domain-specific Processors.



